Object Detection Models
- One vs Two Stage Detection
- Shots in Object Detection
- Popular Models
- Fine-Tuning a YOLO Model
- Conclusion
Object detection models are a subset of computer vision models that seek to identify objects in an image. Using machine learning, detection models create bounding boxes with labels around each object. They differ from classification models in that they are looking for objects in the image rather than at the entire image. Object detection models are used across all industries, notable examples include self-driving vehicles and autonomous robots. Let’s dive into characteristics of Object Detection models, a few popular models, and fine-tune our own model.
One vs Two Stage Detection
Detection models can be grouped in two categories, One and Two Stage Detectors. The stage count refers to how many times an image is passed through a neural network. Two Stage detection was the original standard, first pioneered in 2014 with the release of R-CNN. It was quickly followed by One Stage detection in 2016.
The original R-CNN paper was game changing for the computer vision field. It demonstrated that Convolutional Neural Networks (CNNs) could be used not only for classification but for identifying objects in an image through highlighted bounding boxes.
Two Stage Detection Architecture
- Extract Region Proposals
- Feature Extraction from each region
- Classification of Regions
- Box Refinement
- Non-Maximum Suppression (NMS) - Remove Overlapping boxes
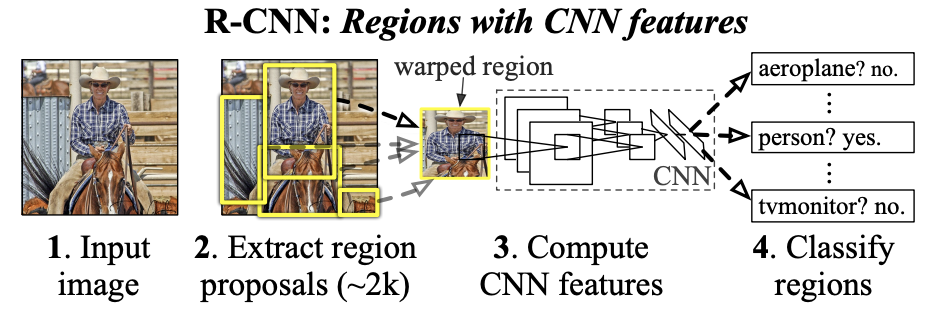
One major challenge with R-CNN and its iterations was the number of steps, models, and overall architecture to manage. Region extraction was executed with an algorithm separate of the CNN. The 2,000 regions are passed to the CNN to generate features. Then a classifier is used to classify each feature before refining the bounding boxes with a regression model. Finally the data is passed to another CNN to apply Non-maximum suppression (NMS) to remove any duplicates or overlapping boxes. Each step can and has been a bottleneck in different implementations resulting in a lot of time and effort to create a smooth processing pipeline.
Object Detection Shots
The number of “shots” for a model refers to how many training examples they require per class.
Full Shot - Aka Standard supervised learning. Full Shot models are trained on a large fully labelled dataset. R-CNN and its later iterations such as Faster R-CNN fall into this boat. Full shot is generally considered to be the most accurate, but its training costs and slower inference can be cost prohibitive in the real world.
Few Shot - The model is trained on a small subset of examples. These models are very useful when large sets of training data is not easy to acquire. Few Shot includes models like YOLO and RT-DETR.
Zero Shot - The newest type of object detection model. Zero shot relies on generalized knowledge and has no training data for its detections. Often times requiring guidance or prompting from the user to identify objects without any previous examples.
Popular Models
You Only Look Once (YOLO) Yolo models perform a single pass on an image, as opposed to earlier R-CNNs which requires thousands of passes per image. The YOLO model has gone through numerous iterations. Some of the recent versions can perform inference at north of 160fps making them great canidates for real-time applications where speed is critical.
Their simple architecture and fast performance have led to strong adoption in the market. While YOLO does come with its limitations such as difficulty detecting small objects.
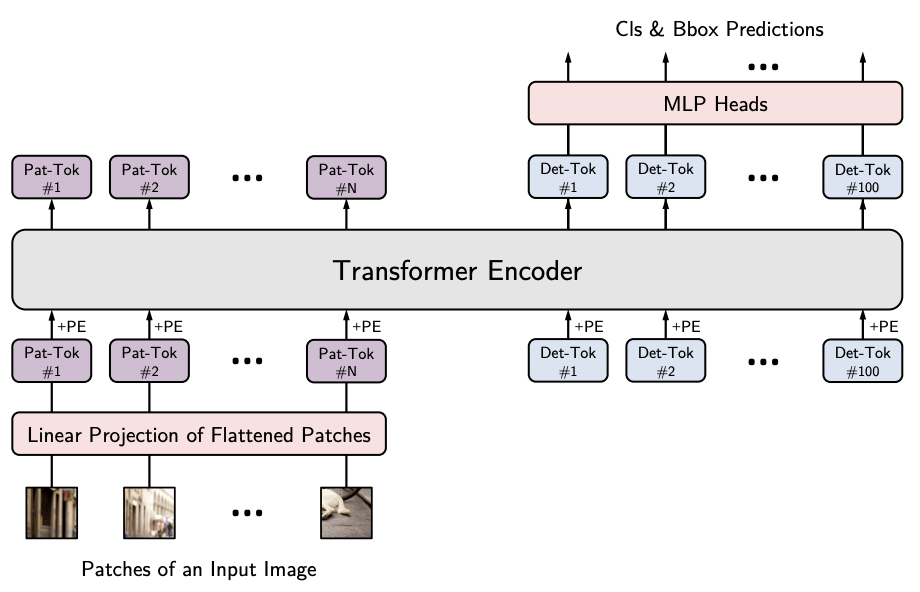
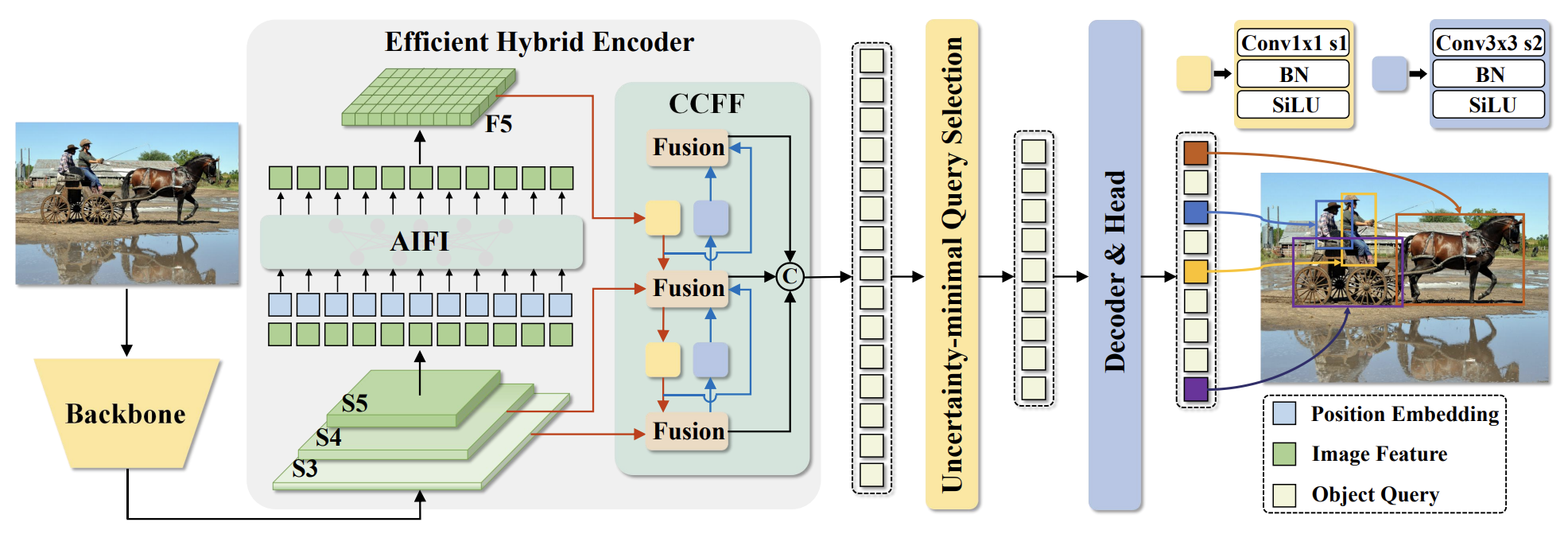
Real-Time (RT) - End-to-End Object Detection (DETR) RT-DETR was created to address the computational costs from YOLO models while serving realtime use cases. YOLO models utilize the same NMS technique above to remove overlapping boxes, this extra analysis can slow down inference or make it prohibitively expensive. RT-DETR leverages the Transformer model architecture to process input sequences in parallel. RT-DETR implements a hybrid encoder to decouple intra-scale interaction and cross-scale fusion resulting in lowered computational costs and improved performance.
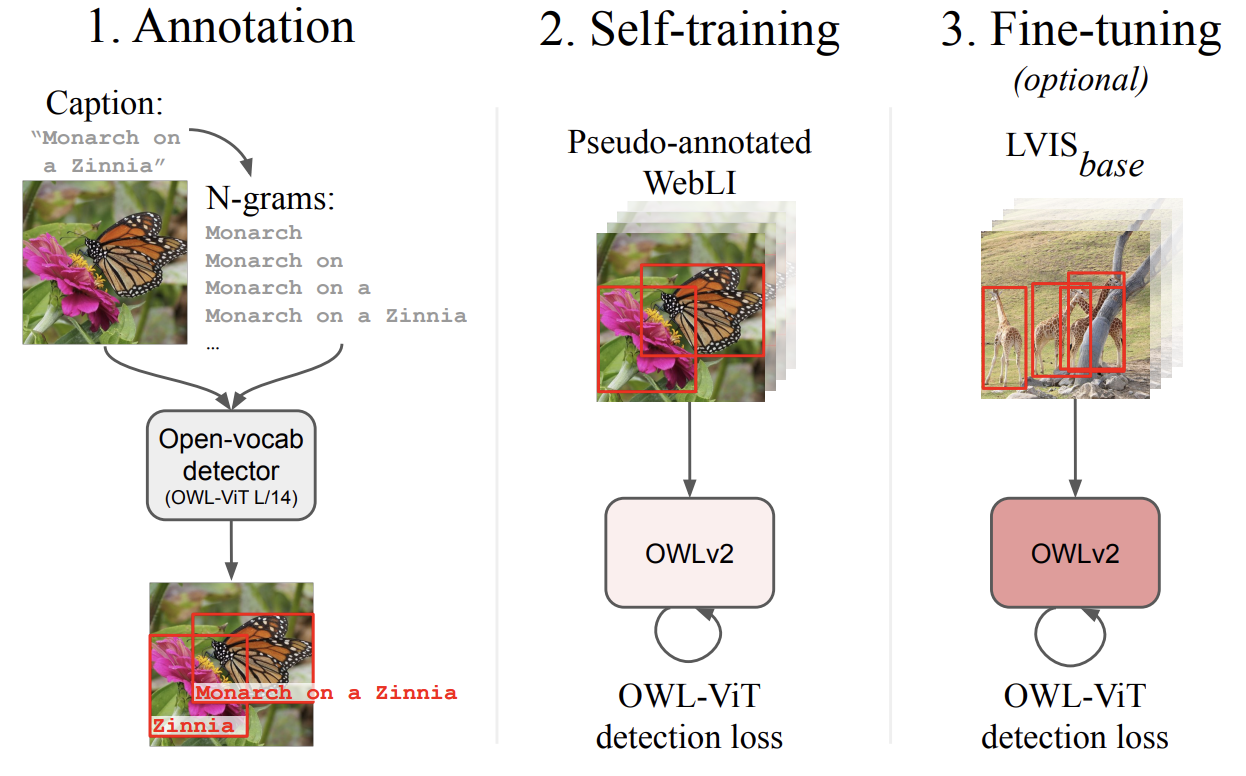
OWLv2 OWL is a zero shot object detection model. It combines user text prompts with its base knowledge to identify objects. This type of model is a new category because it requires no examples, only the context of the prompt to identify objects. OWL is very useful for use cases that may not have useful training data solving the rare item identification problem.
Initial Paper
OWLv2-base-patch16-ensemble
Fine-tuning a YOLO Model
Fine-tuning is a technique that starts with a pre-trained model and adjusts it for a specific task. As an example, say I want to detect Lego Stormtroopers, the YOLO models are trained for ~80 classes, but not Stormtroopers. This is a great use case for fine-tuning. We will utilize the models existing knowledge but give it direction to the types of objects to identify. One of the benefits of fine-tuning is it typically requires less training data and is more performant as it effectively creates hot paths to specific objects.
First, we need to get some training data. I’ve taken ~50 images of Stormtroopers on my table and annotated each of them. It is usually recommended to have 2k-10k images per class, but let’s see how accurate we can get with 50! There are lots of annotation tools, I’ve commonly used label-studio or make-sense . Label-studio is nice because you can export in YOLO format which is a nice speedup.
![[od_bounding_boxes.png]](/assets/od_bounding_boxes.png)
For the demo, we’ll use Ultralytics’s library as it makes working with YOLO models easy, but there are numerous others on huggingface. Let’s download the YOLO 11 model, Ultralytic’s most recent model. The model is in pytorch format, and we can see it includes 80 classes out of the gate.
from ultralytics import YOLO
model = YOLO('yolo11n.pt')
print(f"Number of classes: {len(model.names)}")
print(f"Classes: {model.names}")
I am using the following standard hierarchy for storing the training data.
datasets/
└── stormtrooper/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/
Let’s designate out a yaml file to set the parameters for the model.
path: stormtrooper
train: train
val: val
names:
0: stormtrooper
hsv_h: .015
hsv_s: .7
hsv_v: .4
translate: .3
scale: .5
shear: .01
flipud: .3
fliplr: .5
mixup: .5
auto_augment: randaugment
Now for training the model! I’m on a mac with a M-series chip but if you’re working with a gpu you can use device=cuda.
yolo train data=datasets/stormtrooper.yaml device=mps
After training is complete, the “runs/detect” directory contains reporting on the success of the training. The best version of the model is in “runs/detect/train/weights/best.pt”.
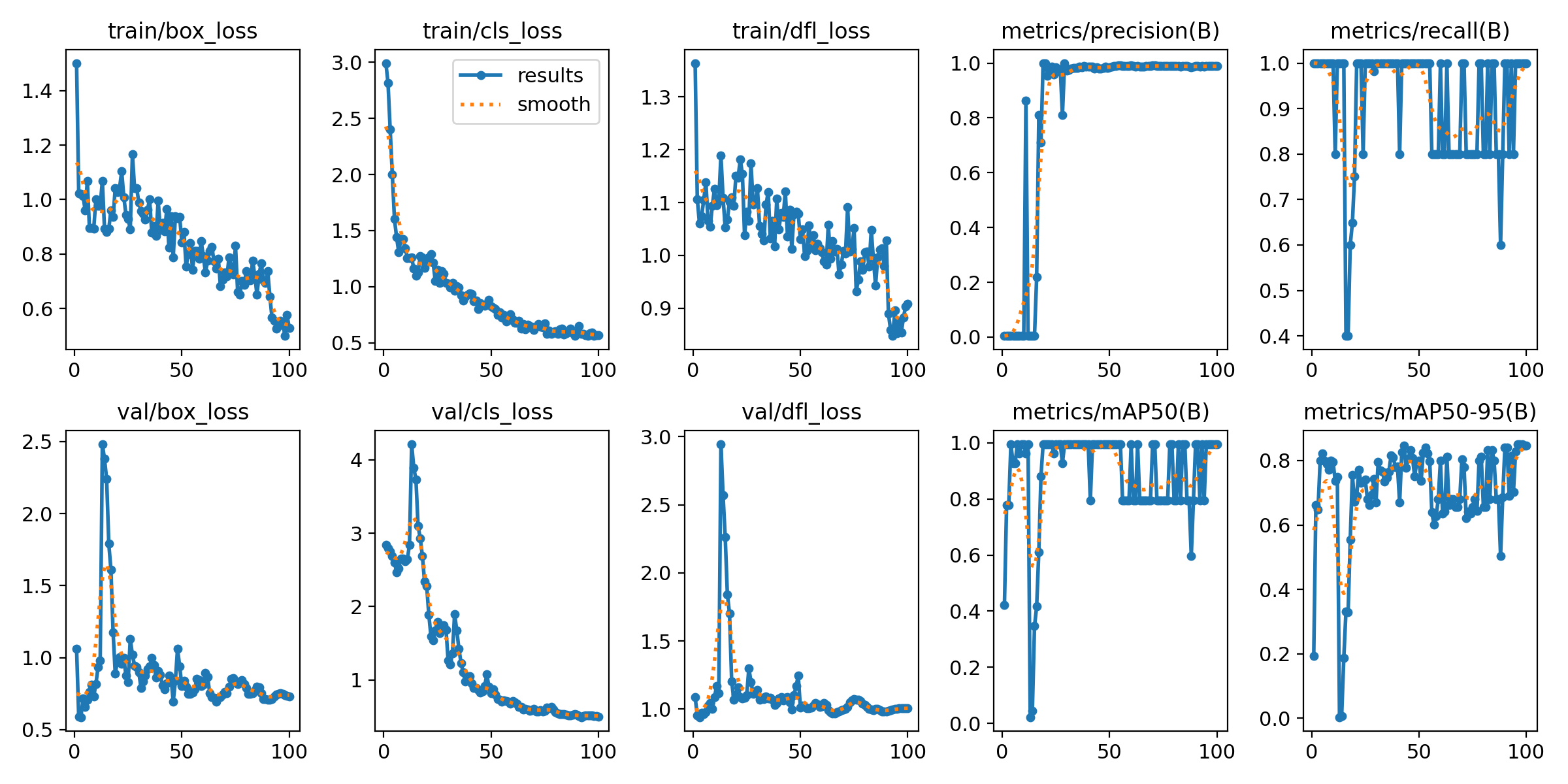
Let’s print the classes for the best model and evaluate it.
model = YOLO('runs/detect/train/weights/best.pt')
print(model.names)
model.val()
mAP50 was 0.995 and mAP50-95 was 0.851. This works for our use case. The scoring is done on a 0-1 scale, so 0.955 and 0.851 will both yield good results in the context of our training data. The difference between the mAP50 and mAP50-95 is the threshold of object overlaps. None of our training data had overlaps so it is expected that the mAP50 has a higher score.
The usefulness of the model is a combination of training data and real world use needs. All our data is trained on a single table, so if the model is only expected to detect Stormtroopers on this table, it’ll perform great. However, if we want to detect objects in different settings and different lighting conditions, a more generalized and larger dataset would likely be required as we’re probably overfitting.
Now let’s do a few predictions and save the results!
model.predict(
'./datasets/stormtrooper/val/images/784e92f8-IMG_1908.jpeg',
imgsz=320,
save=True)

In every frame were were successful in identifying the Lego Stormtroopers. The final trained model is 5.5mb and performant to handle high FPS use-cases. The benefit of YOLO and other newer models is this fine-tuned model could be executed on an edge device and do real-time object detection.
Conclusion
Object detection models have come a long way. They’re now capable of efficiently detecting objects in high FPS environments. Our fine-tuned example was simple with limited training data but it still provided accurate detections.